The impending dominance of robots in our world is almost taken for granted. Smartphones and computers have shown us how useful and versatile technological devices can be, let alone truly intelligent ones.

Vision capabilities in robots is evolving in the same direction as human vision. Courtesy of Pixabay
Arguably the most important part of a robot is its brain. And it is making swift advancements in its capabilities. In fact, imitating the human anatomy seems to have done the trick. Implementing an algorithmic structure resembling our brain’s neuron network has resulted in a series of breakthroughs in the field of artificial intelligence.
Learning to See
The application of such neural networks in algorithms, better known as Deep Learning, has increased the capacities of machines to ‘learn’ particular behaviors. Key is its knack of breaking down data into useful information. That too, without explicit human guidance. Furthermore, the robots’ use of deep learning methods primarily target vision, which is no surprise since a large part of our own brain, close to 50%, is being used to see. We have five senses. Yet vision is definitely the most important means we have of learning about our environment. The usefulness of vision can be broken down into two factors: first, its ability to work from a distance and second, the abundance of the medium it depends on – light.
No wonder therefore that evolution has favored the species that can see. Robots too, therefore, will have to master the art of vision. Our eyes take in light and form an image. The brain then processes to extract information. Similarly, the most direct method for robots to ‘see’ is to give them cameras and capture the world around them to learn from it. But how powerful do these cameras have to be? And what features do they have to have to help the robot interact successfully with his environment?
Recognizing Objects
It is as yet a mystery how the art of sight developed in the course of evolution. To produce such a sophisticated optical system to gain information about the environment is nature’s wonder. Our eyes have a ton of different functions, all of which we must first understand if we want to create their robotic counterpart. The principal function of human eyes is to recognize objects. Our world is filled with a variety of objects, too many for us to count or remember. Yet we almost never seem to have a problem recognizing them. And the more we delve in this ability, the more fascinating it becomes. For instance, we definitely have a memory somewhere of what a dog looks like. So this allows us to compare the object in front and say, “look, there’s a dog.”
But what would that memory contain? Dogs come in a host of colors, shapes and sizes. At the heart of solving this puzzle is pattern detection. And deep learning is really good at it. However, what is remarkable is that for the algorithm to learn what a dog is, it needn’t have learned much. No need to know what eyes, tails, furs or legs are. Neither does the more general information of what animals or mammal are, is provided. It only needs enough images as input. Along with the corresponding information of whether a dog is or isn’t there in that image. And the features needed to detect the presence of a dog in subsequent observations are learned automatically by the algorithm! Come to think of it, our brain works exactly like that. As newborn babies, we learned to distinguish when our mother was in front of us or not. Obviously, we weren’t taught what makes up a mother or who exactly she is.
Extracting Features
While it is not easy to determine why the algorithm gives more importance to certain features over others, researchers have obtained a hierarchy in these features the deep learning algorithm places when determining objects. Almost always, edges and corners of those objects are learned first.

Showing multiple pictures w/o dogs is all that a robot needs to learn to learn to ‘see’ dogs.
This is great news as most cameras have exceptional color dynamics and high contrast ratios. Both facets that highlight edges of objects. Not surprisingly, our eyes and brain prefer sharp and more detailed photography. The improved lens architecture has definitely been a help but the real differential was and still is the image sensor. Perfecting the sensor technology has always been a question of compromise. Putting too many pixels (light receptors) per area increases the resolution. But this also reduces the color dynamics. Despite this, consumer photography has pushed the limits. It is a journey very similar to the increased computing power predicted by the famous Moore’s law. Image sensors have been steadily improving their receptivity of light while constantly increasing the pixel density to capture more detail.
Lucky for us, even decent cameras and sensors available in the market today can serve as eyes for a robot. And combining them with a proficient deep learning algorithm will give it plenty of power to perceive objects. But wait, there is more to vision than perceiving objects.
Recognizing Movements
Objects often move and it would be disastrous for a robot not to realize it is the same object. It can be easily achieved by high-speed cameras some of which capture images several thousand times per second. This freezes the motion allowing deep learning algorithms to easily recognize the object. Our eyes capture only twenty two images per second. So in this domain, robots would do far better than humans.

Most high-end cameras are robot worthy. With color dynamics, contrast ratio, high-speed shutters, and frame rate. All in all, robot vision can rival human sight. Courtesy of Wikimedia Commons
What about detecting the movement itself? How do we distinguish a moving object from a static one? In terms of cameras, high speed cameras would be sufficient. Perceiving movement is more about discerning the differences. The patterns in the slight differences between a series of pictures taken over time of a moving object. This could be done again with deep learning provided the algorithm has learned the concept of movement sufficiently well through sample images. So what is our conclusion? It is that high speed cameras are sufficient optical systems to recognize moving objects and detect their motion.
Depth and Spatial Perception
Both of our eyes don’t see the same image. Especially noticeable is when an object is very close to you. In fact, the separation between your eyes creates a different background of the same nearby object (as shown in the figure below). This effect is called parallax. While it might seem like a nuisance, your clever brain actually uses this difference to gauge how far the object is from its background. Then the distance between the eyes. Along with the difference between the angles formed between the front object and the background. All can be used to calculate the distance to the front object. In other words, the bridge between our eyes is responsible for our sense of depth. And parallax is why we see the 3D world in 3D. Despite each eye capturing only 2D images just like any camera.
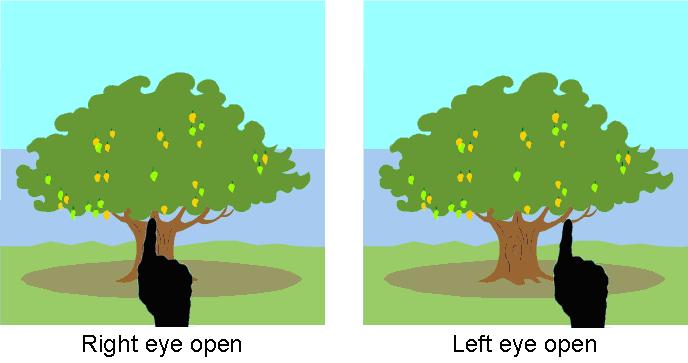
The background behind your finger seems to shift. When looking from the left and then the right eye. Courtesy of The Escapist.
While it would help them look more human, perceiving a 3D world will be the main reason for robots to have at least two cameras. Robotic systems are already using double cameras to perceive depth and gauge distances. Our eyes excel at operating under low light environment. Plus, they can shift focus with ease from far objects to very close ones. Furthermore, the muscles also allow swift rotation to pinpoint almost any direction. And all this does not reduce stability. Our eyes can function even when our entire body is moving.
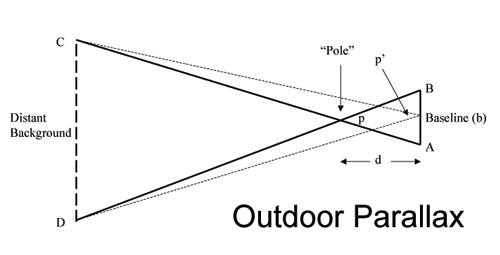
Notice how the distance BA is responsible for the shift in background. Our brain uses this to gauge the distance to the front object. Courtesy of Planet Facts.
Let us put all these requirements on a robot’s optical system. And some powerful sensors to capture details and colors. Also a high speed shutter to freeze movement. While it might significantly increase its cost, it could be well worth it.
Robots Exceeding Human Vision
Thinking beyond, robots need not be limited by human vision. Additionally, there are a host of light-based sensing devices for mapping not necessarily using parallax. LIDAR (Light Detection and Ranging) is an exciting new technology. It makes use of pulsed lasers to measure distances. To an accuracy far outweighing the distance measurement through parallax, surroundings can be measured. Instantly. Google’s self driving cars are one of the first robots to use them as their mapping eyes.
Beyond Visible Light
Could robots also venture outside the visible domain? Actually visible light is only a tiny section of the entire spectrum of Electromagnetic waves. Powerful infrared detectors can be mounted on robots. Then they could perceive heat. In fact, obtaining a thermal image of the world is proving vital to military and exploration robots.
Uniquely, Apple’s iPhone X has introduced a ‘depth’ camera. It combines an infrared system with a regular camera to create a 3D image of the object in front. iPhone users can create a reliable face ID. In fact, it is so secure it even serves as their password for financial transactions. Apple’s tech recognizes the minute details of individual faces and objects. Furthermore, it maps the face onto a 3D map. All in all, this results in an ‘foolproof’ system. Could this be the revolution in providing vision to micro robots?

The new iPhone X’s depth camera is reliable. Enough to serve as a password alternate for financial transactions. And with a 1 in a 1000,000 chance of fooling the system. Courtesy of Mac Rumors
One of the most futuristic developments in robotics is to give them the power to recognize the material content in each object they perceive. Every element has a unique spectral identity. So a set of EM wavelengths emitted and absorbed by it. But could we include a fancy spectrometer as part of the vision system in a robot? Necessity is the mother of invention, after all. And maybe, future robots take over the role of physicians. So they could have x-ray detectors as eyes. But now we are simply entering fantasy land. These are robots after all, not aliens!
[…] by /u/FindLight2017 [link] […]